
La clean architecture est une approche de conception logicielle qui vise à créer des systèmes faciles à comprendre, à maintenir et à faire évoluer.
Elle se base sur des principes fondamentaux qui permettent de structurer le code de manière claire et modulaire, en séparant les responsabilités et en minimisant les dépendances.
Voici les règles de base ainsi que les avantages de cette architecture pour les développeurs et les projets logiciels.
Les règles de base de la clean architecture
Indépendance vis-à-vis des frameworks et librairies
La clean architecture préconise une indépendance totale du code métier par rapport aux frameworks et librairies utilisés. Le code central de l’application ne doit pas dépendre de ces éléments externes, qui sont considérés comme des détails d’implémentation.
Cela permet de changer facilement de framework ou de librairie sans impacter le cœur de l’application. Le code métier reste ainsi pérenne et réutilisable, quel que soit l’environnement technique.
Séparation claire des responsabilités
Chaque composant de l’architecture doit avoir une responsabilité unique et bien définie. Le code est organisé en couches distinctes, chacune ayant un rôle spécifique :
- La couche de présentation gère l’interface utilisateur
- La couche de domaine contient la logique métier
- La couche d’infrastructure gère les détails techniques (accès à la base de données, appels réseau, etc.)
Cette séparation claire facilite la compréhension, la maintenance et les tests du code.
Les différentes couches de la clean architecture
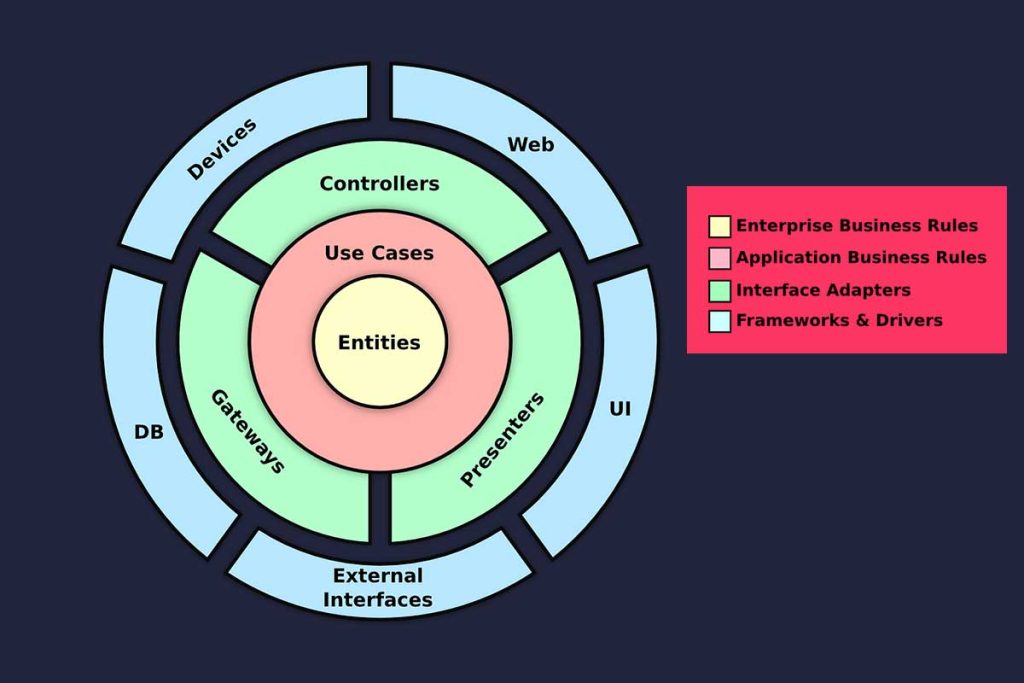
La clean architecture organise le code en plusieurs couches concentriques, chacune ayant des responsabilités spécifiques. Voici un aperçu des principales couches :
| Couche | Responsabilité |
|---|---|
| Entités | Objets métier, règles de gestion |
| Cas d’utilisation | Logique applicative, orchestration des entités |
| Adaptateurs d’interface | Conversion des données entre les couches |
| Frameworks et pilotes | Détails techniques, interactions avec le monde extérieur |
Les couches internes ne dépendent pas des couches externes, ce qui assure une grande flexibilité et une évolutivité du système.
L’indépendance vis-à-vis de l’interface utilisateur et de la base de données
Interface utilisateur découplée
Dans la clean architecture, l’interface utilisateur est considérée comme un détail d’implémentation. Elle est découplée du reste de l’application grâce à des adaptateurs qui convertissent les données entre la couche de présentation et la couche de domaine.
Ainsi, il est possible de changer complètement l’interface utilisateur (passer d’une application web à une application mobile, par exemple) sans impacter le cœur de l’application.
Persistance des données abstraite
De même, l’accès à la base de données est abstrait et isolé dans la couche d’infrastructure. Le code métier ne dépend pas d’une technologie de base de données spécifique, ce qui permet de changer facilement de système de persistance si nécessaire.
Des interfaces et des adaptateurs sont utilisés pour communiquer avec la base de données, rendant le code métier totalement indépendant de ces détails techniques.
La gestion des dépendances externes via des interfaces
La clean architecture préconise l’utilisation d’interfaces pour gérer les dépendances externes, telles que les services web, les bibliothèques tierces ou les systèmes de messagerie.
Au lieu de dépendre directement de ces éléments externes, le code métier définit des interfaces qui décrivent les fonctionnalités dont il a besoin. Des adaptateurs implémentent ensuite ces interfaces et se chargent de la communication avec les services externes.
Exemple d’interface pour un service d’envoi d’e-mails
interface EmailService {
void sendEmail(String recipient, String subject, String body);
}
Cette approche permet de substituer facilement une implémentation par une autre, sans impacter le code métier. Elle facilite également les tests, car il est possible de créer des implémentations « bouchons » (mocks) des interfaces pour simuler le comportement des services externes.
Le rôle du modèle de vue (view model) dans la simplification de la vue
Le modèle de vue (view model) est un composant clé de la clean architecture pour simplifier la couche de présentation. Son rôle est de préparer les données spécifiquement pour l’affichage, en les formatant et en les organisant de manière optimale pour la vue.
Le modèle de vue contient uniquement les données nécessaires à l’interface utilisateur, sans aucune logique métier. Il sert de contrat entre la couche de présentation et la couche de domaine, en exposant des propriétés et des méthodes adaptées aux besoins de la vue.
Avantages du modèle de vue
- Simplifie la vue en la déchargeant de toute logique de formatage ou de transformation des données
- Facilite les tests de la couche de présentation en isolant les données de la logique d’affichage
- Permet de changer facilement de technologie de vue (par exemple, passer d’une application web à une application mobile) sans impacter le reste de l’application
La clean architecture comme facilitateur pour les tests unitaires
La clean architecture favorise grandement la testabilité du code. Grâce à la séparation claire des responsabilités et à l’utilisation d’interfaces, il est facile de tester chaque composant de manière isolée.
Les tests unitaires peuvent se concentrer sur la logique métier, en utilisant des implémentations « bouchons » (mocks) pour simuler les dépendances externes. Cela permet de vérifier le comportement du code dans différents scénarios, sans dépendre de l’infrastructure ou des services tiers.
Exemple de test unitaire pour un cas d’utilisation
public void testUserRegistration() {
// Arrange
UserRepository userRepositoryMock = mock(UserRepository.class);
EmailService emailServiceMock = mock(EmailService.class);
UserRegistrationUseCase useCase = new UserRegistrationUseCase(userRepositoryMock, emailServiceMock);
// Act
useCase.registerUser("[email protected]", "password");
// Assert
verify(userRepositoryMock).save(any(User.class));
verify(emailServiceMock).sendEmail(eq("[email protected]"), anyString(), anyString());
}
En testant chaque composant de manière isolée, on s’assure que le code fonctionne correctement et on détecte rapidement les éventuelles régressions.
Les avantages de la clean architecture pour les développeurs
La clean architecture a de nombreux avantages aux développeurs et aux équipes de développement :
- Meilleure maintenabilité : grâce à la séparation claire des responsabilités et à l’indépendance des couches, le code est plus facile à comprendre, à modifier et à maintenir.
- Flexibilité et évolutivité : l’architecture permet de s’adapter facilement aux changements de technologies ou de besoins métier, sans impacter l’ensemble du système. La Clean Architecture s’aligne bien avec l’approche modulaire et adaptative des Agile UI Toolkits, ces derniers permettant de construire rapidement des interfaces utilisateur évolutives tout en suivant les principes de développement agile.
- Réutilisabilité du code : les composants de la clean architecture sont conçus pour être réutilisables dans différents contextes, ce qui favorise la productivité et réduit la duplication de code.
- Testabilité : la clean architecture facilite l’écriture de tests unitaires et d’intégration, en isolant les différentes parties du système et en utilisant des interfaces pour les dépendances externes.
- Collaboration plus facile : la structure claire et modulaire de la clean architecture permet aux équipes de travailler efficacement ensemble, en se concentrant sur des parties spécifiques du système sans interférer avec les autres.
En adoptant les principes de la clean architecture, les développeurs peuvent créer des systèmes robustes, maintenables et évolutifs, tout en améliorant leur productivité et la qualité globale du code.




